End-to-End Testing for Microservices: A 2026 Guide
Introduction: The E2E Testing Conundrum in Microservices
End-to-end testing has always been a double-edged sword – even more so in the world of microservices. On one hand, E2E tests are critical for validating that all services work together seamlessly in real user flows. On the other hand, many experts warn that heavy reliance on end-to-end testing in a microservices architecture can create a "distributed monolith," slowing down deployments and undermining the very agility microservices promise. There’s truth to that: if done poorly, E2E tests can become brittle, flaky, and a bottleneck that reduces your deployment frequency. Yet, in 2026, engineering leaders are finding that end-to-end testing for microservices remains indispensable – if approached with modern strategies and tools.
This guide takes an opinionated, real-world look at how to make E2E testing effective in a distributed, cloud-native system. We’ll explore both the strategic big-picture (how E2E testing fits into your quality strategy) and the technical nitty-gritty (how to design, automate, and maintain these tests). Importantly, we’ll highlight new solutions like preview environments that finally make reliable, scalable E2E testing achievable on every code change. By the end, you’ll have a playbook for ensuring your microservices-based applications deliver quality without grinding your CI/CD pipeline to a halt.
Why End-to-End Testing Still Matters (Even for Microservices)
Some teams have been tempted to forego end-to-end tests entirely in favor of unit, integration, and contract tests. It’s true that a robust lower-level test suite is essential (the classic Test Pyramid approach) to catch most issues early. In an ideal microservice world, each service is independently deployable after passing its own tests. Contract tests between services can verify interactions without full system tests. User acceptance tests (UAT) can cover business-level validation separately.
So why do E2E tests at all? In practice, end-to-end testing in microservices provides a critical safety net:
- System Integration Confidence: E2E tests ensure that all services and components work together as a cohesive system in a production-like scenario. They catch misconfigurations, integration errors, or data flow issues that unit and integration tests might miss.
- Regression Detection Across Boundaries: When dozens of independent services evolve, it's easy to introduce changes that don’t break a single service’s tests but do break a cross-service workflow. End-to-end tests can detect these regressions before users do.
- Validation of Real User Journeys: E2E tests simulate real user interactions – often spanning UI, APIs, databases, and third-party integrations – to validate that the customer’s experience is as expected. This is something no amount of isolated testing can fully guarantee.
- Confidence in Complex Releases: For engineering leaders, a passing E2E suite is a final gut-check before green-lighting a release. Especially for mission-critical systems or regulated industries, that end-to-end validation is non-negotiable for peace of mind.
In short, while you should minimize frivolous E2E tests, well-designed end-to-end tests remain vital for microservices architectures to ensure quality at the system level. The key is to address the challenges that make E2E testing “impractical” in naive implementations – and that’s exactly what we’ll cover next.
Key Challenges in End-to-End Testing for Microservices
Testing an entire distributed system end-to-end is inherently tricky. Engineering managers and CTOs often encounter these major challenges when implementing E2E tests in a microservices environment:
Service Orchestration & Environment Complexity
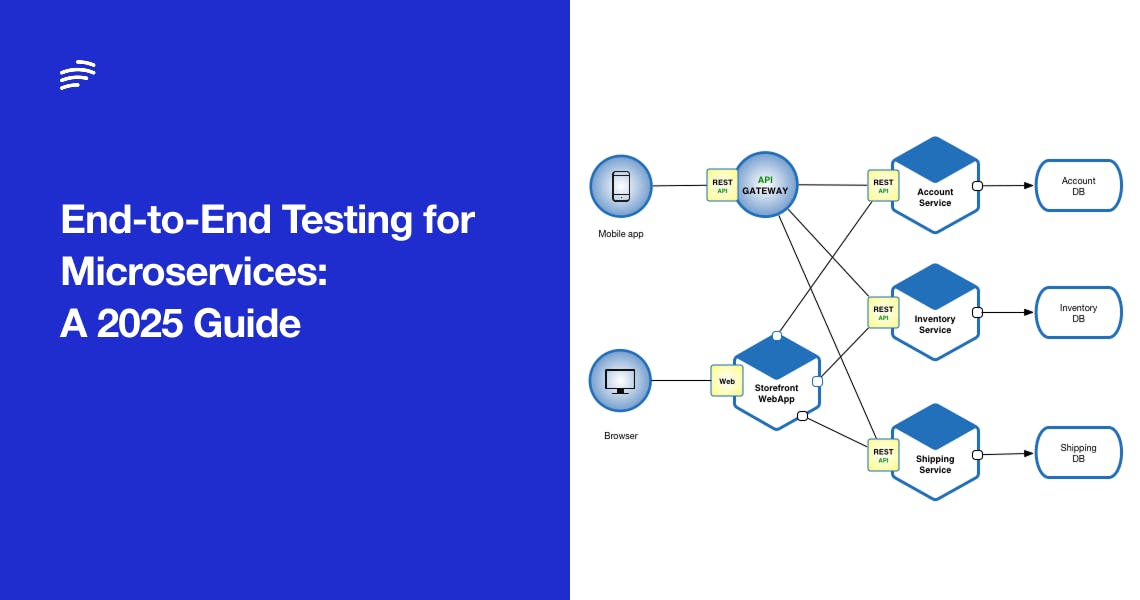
A microservices application might consist of tens or hundreds of services, each with its own dependencies (databases, caches, external APIs, etc.). Orchestrating all these components into a test environment is a massive undertaking. Unlike a monolith, you can’t simply deploy one artifact and run tests; you need a way to deploy and coordinate multiple services, in correct versions, with proper configuration, all at once.
Setting up a test environment that closely resembles production is difficult and costly. Many teams maintain a shared staging environment where all services are deployed – but sharing environments leads to contention, configuration drift, and “works on my machine” headaches. As Lukas Pradel noted, replicating a production-like environment for testing is technically doable, but in practice, the heterogeneity of services and teams makes even “innocent” tasks – like feeding services with consistent test data – quite challenging. The more microservices and infrastructure pieces you have, the more complex and slow your end-to-end test setup becomes.
Why it’s hard: You must manage service orchestration for tests: ensuring all required services spin up (or are stubbed), configuring them with the right endpoints and data, and orchestrating calls between them in a test scenario. Traditional solutions include using container orchestration (Docker Compose, Kubernetes) to bring up a full stack for testing, but doing this reliably for each test run is resource-intensive and brittle. Every external integration (third-party APIs, legacy systems) needs to be either included or simulated. The complexity often leads teams to limit E2E testing to a pre-production environment that is perpetually “almost like prod” – with all the maintenance overhead that entails.
Unlock Scalable End-to-End Testing for Microservices
Stop letting test environments block your pipeline. Preview environments give you full-stack, per-PR deployments to test complex workflows earlier and faster.
Flaky Tests and Distributed Unreliability
Flaky tests – tests that sometimes fail for unclear reasons and pass on re-run – are the bane of any test suite, but they particularly plague microservices end-to-end tests. In a highly distributed system, “your tests will fail often for a myriad of reasons… There’s just so many things that can go wrong,” as one microservices testing expert put it. A few common causes of flakiness in E2E microservices tests include:
- Timing and Race Conditions: Services communicate over networks and often asynchronously. A test might assume data is propagated or a downstream service has responded, but in reality there’s a race condition or slight delay. One run, the timing is fine; the next run, a downstream service hasn’t updated in time, and the test fails. These issues are intermittent and hard to reproduce.
- Eventual Consistency: Modern architectures (e.g. event-driven microservices) embrace eventual consistency, but a test expecting immediate consistency might intermittently see stale data. Without careful handling (like waiting for events or using retries), tests can flicker between pass/fail.
- Environment Variability: In a shared env, one test could be impacted by leftovers from another. If microservice A’s state is altered by a previous test, a subsequent test involving A and B might fail unexpectedly. Test order or parallel test interference can cause non-deterministic failures.
- Infrastructure Quirks: Network blips, container startup time variance, memory/CPU contention – all can surface as random failures in different test runs. For example, a slow API response due to a noisy neighbor on the test cluster might trigger a test timeout one out of ten runs.
Flaky end-to-end tests are more than an annoyance; they undermine trust in the test suite and slow down CI/CD. Engineers waste time investigating “false positives” and might even start ignoring E2E test results (defeating their purpose). The challenge for engineering leaders is to design E2E tests and environments that minimize flakiness and to implement processes to quickly detect and fix flaky tests when they arise.
Test Data Consistency and Isolation
Data management is a subtle but significant challenge in E2E testing of microservices. In a monolith test, you might reset a single database between tests. In a microservices scenario, each service might have its own database or data store. Ensuring data consistency across services for a test scenario can be very tricky. For example, a complex user workflow might touch the User service’s DB, the Orders service’s DB, and a Inventory service. To simulate a realistic test, you need a coherent initial state: e.g., a test user exists in all the right places, with the right permissions and associated records. Maintaining referential integrity of test data across distributed services is essential – otherwise, your test might fail not because of a bug, but because the data assumptions were wrong.
Moreover, if tests run sequentially or in parallel on a shared environment, one test’s data actions could interfere with another. A classic issue is test isolation: test A creates a record that test B inadvertently picks up, causing unpredictable results. Or two parallel tests both try to modify the same data in a shared database, causing conflicts.
Best practices require carefully seeding test data for each end-to-end test (or suite) and cleaning it up afterward. This might involve database migrations or fixtures for each microservice datastore. Some teams version-control their test data or use data fabrication and subsetting techniques to generate realistic datasets. In any case, test data setup for microservices is a non-trivial effort. Many failures in E2E tests ultimately come down to “data not in the state the test expected.” Without a solid strategy for consistent and isolated data, E2E tests will be fragile.
API Contract Mismatch and Integration Errors
One common source of end-to-end test failures in microservices is an API contract mismatch between services. Microservices often communicate via APIs or messaging; if Service A expects Service B to return data in a certain format or fulfill a certain behavior, and B’s contract changes, end-to-end tests may catch the integration break. These failures can be subtle – perhaps a field was renamed or an error code changed. Ideally, contract testing at the integration level should catch such issues earlier. In practice, not every integration is covered by contract tests, and E2E tests end up being the safety net that validates that all service interfaces and assumptions line up correctly.
This is challenging because a failing E2E test only tells you something went wrong when services interacted; it can be laborious to pinpoint which service or interface was the culprit. For example, an end-to-end test of a checkout process might fail with an incorrect total price – is the bug in the pricing microservice, the tax calculation service, or the API gateway aggregation logic? Debugging that can require digging through logs across multiple services.
To mitigate this, teams are increasingly adopting contract tests and integration tests between services. However, a governance challenge remains: ensuring all teams keep their API schemas and expectations in sync. In the absence of diligent contract testing, end-to-end tests often double as contract validation tests (implicitly). They highlight where one service’s change has broken another. Engineering leaders should treat frequent E2E failures as a sign that more upfront contract validation may be needed. In other words, strengthen the design and communication of service interfaces so that your E2E suite isn’t constantly catching contract violations that should have been prevented.
Observability and Debugging of Failures
When an E2E test that touches 5 different microservices fails, how quickly can your team figure out why? In a monolith, you’d open a log and see a stack trace. In a microservices system, an error could originate deep in one service and propagate as a generic failure at the end. Observability – the combination of logging, monitoring, and tracing – is crucial for diagnosing end-to-end test failures. Without strong observability, E2E tests become “black box” tests where “it’s not trivial to locate the cause of an error”.
Challenges include:
- Distributed Traces: If you have distributed tracing (e.g. using OpenTelemetry, Jaeger, etc.), you can trace a test transaction across services. But setting up tracing in test environments and making sure each test can easily fetch the trace is a non-trivial effort. Many teams lack comprehensive tracing in non-prod environments.
- Aggregated Logging: You need a way to quickly get logs from all services for the timeframe of the test. Sifting through logs service-by-service is slow. Without centralized logging and correlation IDs that tie logs together by request, debugging is like finding a needle in a haystack.
- Monitoring & Alerts: Sometimes an E2E test fails due to an environment issue (e.g., a service was OOM killed, or a network partition). If your monitoring isn't active in test environments, you might not realize the cause. Observability tooling in test setups often lags behind production-grade monitoring.
Engineering leaders should invest in making test environments observable just like production. That means enabling application telemetry during tests, using correlation IDs for test transactions, and giving developers self-service access to logs and dashboards for the E2E environment. When a test fails, your team should be able to quickly ask “what happened?” and get an answer from the tools, rather than guesswork.
CI/CD Pipeline Bottlenecks and Slow Feedback
Perhaps the biggest strategic challenge with microservices end-to-end testing is how it impacts your CI/CD pipelines and release speed. By their nature, E2E tests are slower and more resource-intensive than unit or integration tests – they might require deploying many services and running lengthy scenarios. If not managed carefully, they become a gating factor that slows down every merge or release.
Common pain points include:
- Long Test Durations: An end-to-end test suite for a complex app can easily take tens of minutes or even hours to run, especially if tests run serially in a shared environment. This slows down the feedback loop for developers and delays deployments.
- Sequential Environments: Many organizations have a single “staging” environment where E2E tests run. Teams end up queuing for this environment. If one test suite is running, others wait. A failure might lock the environment until fixed. As described by Pradel, one failing test can stall the pipelines of all the services involved – teams are stuck in a dreaded “deployment window” waiting for the environment to be free and green.
- Resource Bottlenecks: If you try to spin up full environments for testing frequently, you might hit infrastructure limits (e.g. not enough test clusters or compute quota), causing delays or forcing tests to run in smaller batches.
- Coupling and Coordination: Because E2E tests often involve multiple teams’ services, a failure may require cross-team coordination to debug and fix. Meanwhile, other changes are piled up behind the failing test. This creates a ripple effect: your theoretically independent microservice teams now have a synchronous dependency in the form of a shared E2E gate. It’s a mini waterfall model reintroduced by testing. This undermines team autonomy and slows down continuous delivery.
All these factors can significantly reduce deployment frequency and agility if E2E tests are not handled smartly. The challenge for 2026 is to get the benefit of end-to-end testing (quality assurance) while avoiding it becoming a choke point in your DevOps pipeline.
In summary, end-to-end testing in microservices is fraught with pitfalls: complex orchestration, flaky tests, data hassles, debugging difficulty, and pipeline slowdowns. If this list sounds daunting, don’t worry – next we’ll discuss how to overcome each of these challenges with a combination of best practices and modern tooling. The goal is to make E2E testing resilient, maintainable, and even fast, turning it from a necessary evil into a competitive advantage for your engineering team.
Best Practices for Resilient E2E Testing in Microservices
Designing and running end-to-end tests in a distributed system requires a disciplined approach. Below are best practices – both strategic and tactical – to ensure your E2E tests provide value without becoming a burden:
- Embrace the Test Pyramid (Minimize Over-reliance on E2E): Use end-to-end tests sparingly and intentionally. A common anti-pattern is treating E2E as the primary way to verify functionality. Instead, push as much testing as possible down to unit and integration tests, which are easier to scale and maintain. Aim for a pyramid where a small number of critical user journeys are covered by E2E tests (e.g. 5-10% of total tests), and the rest by faster tests. This reduces the surface area for flaky failures and shortens execution time. In practice, this means designing E2E tests only for high-value scenarios – core business flows, major app interactions, and things that absolutely must work in production. Resist the urge to test every edge case end-to-end; cover edges with lower-level tests.
- Use Contract Tests to Catch Issues Early: Invest in API contract testing between services so that mismatches are caught during the development of each service, rather than in a broad E2E test. Contract tests (often consumer-driven contracts) validate that for each pair of service consumer and provider, the expectations are aligned. While contract tests require maintenance, they significantly reduce integration failures and make your E2E suite more stable. As a bonus, well-defined contracts encourage teams to communicate and design better interfaces. The result is fewer surprises when everything is integrated. Prioritize contract tests for critical service interactions (e.g., payment service ↔ order service) so that E2E tests aren’t the first line of defense for those connections.
- Isolate and Reset Test Data: Treat test data management as a first-class concern. Ensure each end-to-end test (or test run) works with a fresh, predictable dataset. This may involve automating database resets or using tools like Testcontainers to spin up ephemeral databases with seeded data for each test. Use unique identifiers or test tenants to avoid cross-test contamination. For example, you might prefix all data in a test with a test run ID, so that concurrent tests don’t clash. Implement teardown procedures to clean up any state. The goal is deterministic tests – given the same code, they should pass every time, regardless of run order or concurrency. If truly isolated data per test is impossible on a shared environment, consider serializing tests by domain or having dedicated environment instances for certain suites.
- Design Tests for Resilience: Write your E2E test scripts to be resilient to minor delays and asynchronous behavior. This means adding appropriate retries, waits, and timeouts around steps that involve eventual consistency. For instance, if a user action triggers an email service, your test shouldn’t immediately fail if the email isn’t instant – instead poll an API or database until a reasonable timeout. However, avoid simply increasing waits to mask race conditions; whenever you add a wait, understand why it’s needed and whether the system provides a way to know when the state is ready (e.g., a webhook or a status poll). Use idempotency where possible: tests should be able to rerun without side effects. If your E2E tests occasionally hit external APIs or services, build in fallbacks or simulate those interactions to reduce flakiness from outside variability.
- Keep Environments Production-Like and Consistent: “Keep your production and test environments as similar as possible” is a mantra for reliable testing. In practice, this means using the same infrastructure-as-code to provision test environments as you do for prod, the same container images, and similar configurations (with only necessary differences). Configuration drift is the enemy of E2E reliability – if your staging environment lags behind, tests might pass there but fail in prod. Use infrastructure automation (Terraform, Kubernetes manifests/Helm, etc.) so that you can reproduce environments on demand. Containerization and virtualization can help simulate prod-like conditions (network latencies, resource limits) in tests. By minimizing differences, you ensure that passing E2E tests truly indicate a high chance of success in production.
- Leverage Full-Stack Preview Environments: One of the most impactful modern practices is to use ephemeral preview environments for end-to-end testing. Instead of funneling all tests through one shared stage, you spin up a complete, isolated environment for each branch or pull request. Platforms like Bunnyshell (an Environment-as-a-Service tool) can automate the deployment of a full microservices stack on demand, using your real infrastructure definitions. This approach addresses multiple challenges:
- You get environment consistency – every test run starts from a clean slate with known state, reducing flakiness.
- Tests for different features or teams can run in parallel, each on their own environment, eliminating bottlenecks and “queueing” for env access.
- Developers can even get a personal URL to manually verify the feature in the preview environment, catching issues that automated tests might miss, all before code merges to main.
- Integrating preview environments per PR means your E2E tests shift left – catching integration problems earlier, when they’re cheaper to fix. An example workflow: a new PR triggers CI to call the environment API, bringing up all required microservices with production-like config; the CI then runs the end-to-end test suite against that environment’s URL, and tears it down if tests pass. This all happens in a sandbox, without impacting others. By the time you merge, you have high confidence in that change’s behavior in a full system.
- Implement Observability in Test Runs: Don’t treat the E2E test environment as a black box. Equip it with the same observability stack as production. This means:
- Include logging and monitoring agents in your test deployments. At minimum, aggregate logs from all microservices (e.g., to an ELK stack or cloud logging service) so that when a test fails, engineers can quickly search across all service logs by timestamp or correlation ID.
- Utilize distributed tracing for key flows. For instance, generate a trace ID at the start of an end-to-end test and pass it as a header through all service calls; this lets you pull a trace report showing the path of that test through the system and where it slowed or failed.
- Set up alerting (even if just to a Slack channel) for test environment issues like service crashes or high error rates. This proactive approach can sometimes catch problems before the test fails or give immediate clues if it does.
- Provide tooling for developers to easily reproduce a failing scenario – for example, the ability to deploy a broken state of the environment to debug, or access to databases/snapshots from a failed run.
- Observability turns E2E failures from mysterious red marks into actionable insights. Engineering leaders should champion investments in this area – it pays off by dramatically reducing the mean-time-to-diagnose when something goes wrong, thereby keeping the pipeline fast.
- Optimize CI/CD Pipelines for E2E: End-to-end tests will never be as fast as unit tests, but you can mitigate their impact on pipeline duration. Some tips:
- Parallelize test execution: If you have dozens of E2E scenarios, split them across multiple environment instances that run in parallel. Many CI systems and EaaS platforms support spinning up multiple environments concurrently (with proper isolation) to cut total time. For example, if you have 40 E2E tests taking 1 hour sequentially, running 4 groups in parallel could cut that to 15 minutes.
- Nightly full runs vs. PR smoke tests: For large suites, consider running a smaller critical subset of E2E tests on each PR (smoke tests) and the full suite in nightly or periodic builds. This way, every commit gets some end-to-end coverage quickly, and deeper coverage happens out-of-band (with failures flagged for triage).
- Resource management: Take advantage of on-demand cloud resources to scale test environments when needed. If your pipeline is slow because it waits for servers, configure autoscaling for your test clusters, or use cloud-hosted ephemeral environments that start in seconds. The ROI of a faster feedback loop is huge.
- Fail fast and provide context: If a certain setup step fails (e.g., one microservice failed to deploy), abort quickly and surface the error clearly. Don’t let the pipeline time out after an hour in such cases. Likewise, when tests fail, ensure the failure reports include as much info as possible (logs, screenshots, traces) so developers don’t have to rerun just to see what happened.
- Governance: Ownership and Maintenance of E2E Tests: End-to-end tests in microservices require a clear ownership model. Because these tests cut across services, you should define how they are created and maintained:
- Some organizations have a dedicated quality engineering team responsible for system-level tests. This can work, but be careful to avoid silos; the QE team must work closely with service teams to understand features and update tests.
- An alternative is a guild or task force of engineers from each microservice team that collaborates on E2E testing. They ensure new features have coverage and that tests stay up-to-date when services change.
- Establish a process for triaging E2E failures. When a test fails, who investigates first? How do you notify potentially affected teams? Having a rotation or defined responsibility prevents issues from falling through cracks.
- Regularly review and prune the E2E suite. As systems evolve, some end-to-end tests may become obsolete or redundant. Eliminating them keeps the suite lean. Also, track flaky tests: if a test is persistently flaky, mark it as such and prioritize fixing it or rewriting it. A culture of keeping the E2E suite healthy is essential – treat it as critical infrastructure, not an afterthought.
By following these best practices, you’ll transform your end-to-end testing from a fragile bottleneck into a robust safety net. It is possible to have microservices and still test end-to-end with confidence – but it requires intentional architecture, the right tooling (particularly around environments and automation), and continuous attention to test quality.
Validate Microservices with Confidence – Before You Merge
Run realistic end-to-end tests for every feature branch. Bunnyshell automates full-stack preview environments so your E2E tests work like production – fast, reliable, and self-contained.
Preview Environments: A Game-Changer for Microservices E2E Testing
It’s worth delving deeper into preview environments, as they have rapidly become a cornerstone of reliable E2E testing in 2026. A preview environment is a temporary, full-stack environment that mimics production, created on-demand (often per pull request or feature branch) and torn down when no longer needed. Here's why preview environments are especially valuable for microservices end-to-end testing:
- Full-Stack Isolation: Each preview environment contains all the services (and databases, etc.) your application needs, deployed in isolation. This means your end-to-end tests aren’t competing for a shared staging environment – no more “who reset the test DB?” or “which version of the auth service is deployed today?” Each PR gets a fresh instance with a known good state. Tests run on that environment can safely assume they have the whole system to themselves.
- Early Integration Testing: Instead of waiting until code is merged into a common environment, developers get immediate feedback on integration issues. As soon as a feature branch is ready, a preview environment can be spun up and E2E tests (and manual exploratory tests) run against it. This catches compatibility issues between services before they hit your mainline branch. Essentially, you shift E2E testing left, fitting into the pull request review process.
- Parallelism and Scalability: Modern Environment-as-a-Service platforms (like Bunnyshell) enable you to run many environments concurrently – even for complex apps with dozens of microservices. Smart deployment algorithms allow launching hundreds of ephemeral environments without melting down your Kubernetes cluster. For example, by deploying services in parallel where possible and queuing intelligently when resources are limited, these platforms make it feasible that every developer (or every CI build) can have its own E2E sandbox. This parallelism obliterates the bottleneck of a single shared test environment.
- Production-Like Fidelity: Preview environments are usually built from the same templates and configs as prod (just with smaller sizing). You can include all the real services, use production-like data (or a sanitized subset), and even incorporate configuration toggles to simulate various conditions. Because they are ephemeral, you can also experiment safely – e.g., spin up a preview environment with a new version of a service to run E2E tests against it, without affecting anyone else. This makes testing of microservices in combination much more flexible.
- Per-PR Observability and QA: When a preview environment is created, stakeholders beyond developers can jump in. QA engineers, product managers, or even customers (in UAT scenarios) can visit the live preview URL to validate the new feature in a full system context. They can do exploratory testing, sanity-check UX, etc., all before code is merged. Any bugs found can be fixed on the branch, and a new environment spun up. This dramatically reduces the chance of finding integration bugs late in the cycle. Moreover, since each environment is short-lived, they inherently encourage automation – you integrate them with CI to run the test suite automatically on deployment.
- Integration with CI/CD: Preview environments are typically triggered by CI pipelines and integrated into your workflow. For instance, upon a pull request, you might have a workflow like: CI builds the images → calls the preview environment API to deploy them → runs E2E tests on the environment → reports results. If tests pass, the PR can be merged with confidence; if not, the environment remains available for debugging. With full API control and CLI tools, teams can script these processes easily. This tight integration means you maintain continuous end-to-end testing without manual steps. Essentially, every code change is proven in a prod-like setting as part of the pipeline.
- Example – Bunnyshell’s Approach: Bunnyshell (to mention a concrete platform) provides full-stack preview environments for every PR – including backend services, databases, and any dependencies – with no code changes required. It automates the heavy lifting of environment setup (using your Docker/Kubernetes configs), and tears down environments automatically to save resources. Notably, it allows running “thousands of environments, without crashing your cluster” through smart orchestration, which is crucial when you have 100+ microservices and many parallel PRs. By removing the overhead of maintaining test environments, it frees teams to focus on writing good tests and code. Many teams report that adopting such ephemeral environments has cut their testing and release cycles from weeks to days, all while improving confidence. (The key is that it’s non-promotional – preview environments can be implemented in-house too – but having a tool makes it far easier.)
In summary, preview environments solve some of the thorniest issues of microservices testing: they provide realistic test beds on demand, reduce flaky tests caused by environment issues, and eliminate scheduling bottlenecks. Engineering leaders should strongly consider incorporating preview environments into their testing strategy. Start perhaps with a pilot on one critical application or workflow, demonstrate how it enables faster feedback and more reliable tests, and then scale it out. In 2026, this approach is moving from cutting-edge to best practice, as organizations realize that investing in ephemeral environment automation yields major dividends in quality and speed.
Conclusion: Quality at Speed – Next Steps for Engineering Leaders
End-to-end testing for microservices is undoubtedly challenging – but as we’ve argued, it’s a challenge worth tackling head-on. With the strategies and tools available in 2026, you no longer have to choose between fast deployments and thorough system testing. By adopting a balanced approach (strong unit and contract tests under a lean set of high-value E2E tests), and by leveraging technologies like full-stack preview environments, engineering leaders can have their cake and eat it too: enjoy the agility of independent microservices and the assurance of integrated end-to-end validation.
Moving forward, here are some concrete next steps and takeaways:
- Audit Your Test Suite: Take stock of your current E2E tests. Are they flaky or slow? Identify quick wins (like fixing a brittle wait or improving data setup) to boost stability. Also, pinpoint any critical user flows not covered by E2E tests – you’ll want to add those for safety.
- Strengthen Foundations: Ensure each service team is practicing solid unit, integration, and contract testing. End-to-end tests should not be catching basic bugs or mismatches that could be caught earlier. Invest in training or tools for contract testing if it’s missing; it will pay off by reducing E2E failures.
- Invest in Environment Automation: Evaluate solutions for managing test environments. This could mean improving your in-house deployment scripts or trying out an EaaS platform like Bunnyshell to automate preview environments. Start integrating ephemeral environment creation into your CI/CD pipeline for at least one key workflow. Measure the impact on test reliability and developer velocity.
- Enhance Observability: Treat test failures with the same seriousness as production incidents. Set up the logging, tracing, and monitoring needed to troubleshoot quickly. Encourage a culture where developers actively monitor and learn from E2E tests results, rather than dreading them.
- Governance and Culture: Make end-to-end quality a shared responsibility. Whether via a dedicated QA team or a cross-team guild, ensure there’s clear ownership for maintaining E2E tests. Celebrate finding bugs in E2E (it prevented a prod issue!), but also treat repeated E2E failures as a learning opportunity to improve process or design. Over time, aim to reduce flaky incidents to near-zero through systematic fixes.
For experienced engineering managers and CTOs, mastering end-to-end testing in microservices is part of driving engineering excellence. It’s about instilling confidence that you can ship swiftly without breaking things. By applying the best practices outlined in this guide, you’ll not only tame the complexity of microservices E2E testing – you’ll turn it into a competitive advantage. Teams that reliably deliver high-quality software at speed are the ones that win in today’s market. End-to-end testing, done right, ensures you’re among them.
Ultimately, remember that end-to-end tests are there to serve you, not shackle you. If they are implemented with care – scoped to what matters, architected for resilience, and enabled by the right automation – they become a powerful ally, allowing your microservices architecture to truly flourish with confidence. Here’s to building systems that are both fast-moving and rock-solid!
Run End-to-End Tests for Every PR Without Slowing Down
Eliminate shared staging chaos and flaky tests. With preview environments, your team can test every change in isolation before merge – with production-like fidelity and full automation.
