
Storing Files In Today’s Cloud: What Is Object Storage
Right now, we’re experiencing an exploding growth in the amount of data we generate. Moreover, this data is unstructured. This means that the** traditional storing solution** of using relational databases with rows and columns is** no longer efficient**.
Because of this, a new technique called object storage has been proposed. There are many resources on the internet that cover what is object storage, but they don’t clearly explain why you should abandon your existing storage solution and implement this one instead.
So, in this article, we want to shed some light on:
- what object storage is;
- why you should use object storage;
- object storage vs. block storage vs. file storage;
- common use cases for object storage.
Let’s begin!
What is Object Storage?
Simply put, object storage, or object-based storage, is a data storage architecture that manages data as distinct units called objects. Each object includes the data itself, a variable amount of metadata, and a globally unique identifier.
Further, object storage devices can be aggregated into larger storage pools, and these pools can be distributed across multiple locations. This enables not only unlimited scale but also data resiliency and disaster recovery.
Because of this, object storage is used to retain and manage massive amounts of unstructured data, such as Facebook photos, Spotify songs, or Dropbox files.
How Object Storage Works
Let’s suppose you want to store all the books in the world in a very large library system on a single platform. There are two things you need to store:
- the contents of the books (data)
- and the associated information like author, publisher, publication date, etc. (metadata).
Traditionally, you would do this using a relational database, organized in folders under a hierarchy of directories and subdirectories. But because we’re talking about a vast amount of books, the search and retrieval process becomes cumbersome and time-consuming when you want to access a specific book.
Instead, object storage is a better choice because the data is static or fixed (neither the contents of the books or the associated information will change).
In this case, the objects (data, metadata, and ID) will be stored as “packages” in a flat structure that’s easily located and retrieved with a single API call. In the future, as the number of books will grow, you can aggregate storage devices into larger storage pools and distribute these storage pools for unlimited scale.
Object storage use cases
Besides the storage of unstructured data, object storage can be used for:
- storage of backup files, database dumps, and log files;
- large data sets;
- archiving files in place of local take drives.
Object storage vs. block storage vs. file storage
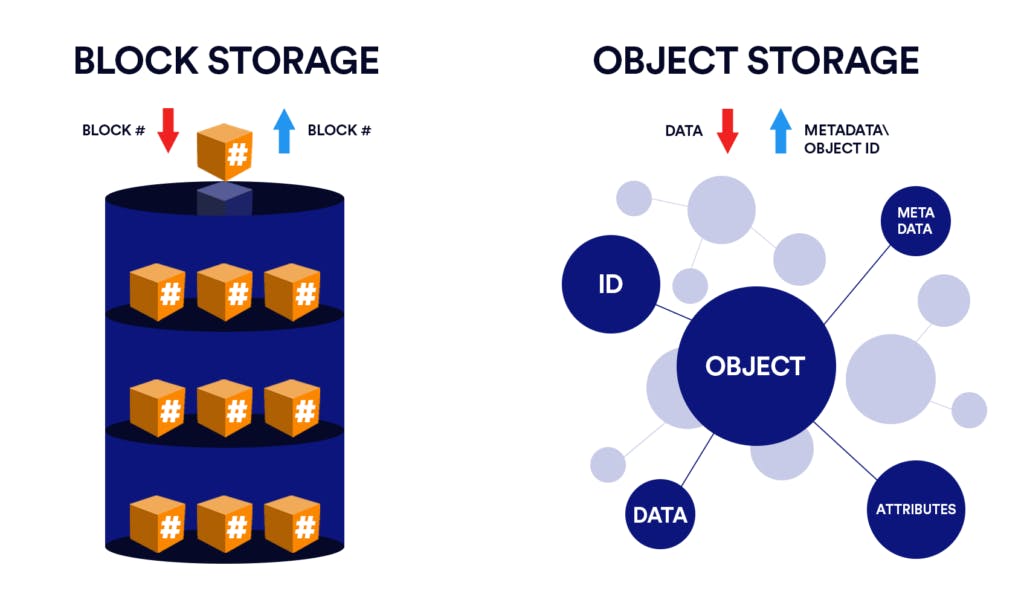
There are fundamental differences between file storage and object storage. File storage organizes data hierarchically inside directories, sub-directories, and files. It works great when the number of files is not very large and you know exactly where they’re stored.
Object storage, on the other hand, typically presents itself via a RESTful API – there’s no concept of a file system. Instead, applications save objects (files + additional metadata such as the file name, the date it was created, and the date it was last modified) to the object store using the PUT or POST API, and the object storage saves the object somewhere in the system.
Then, the application receives a unique key (think of it like the number you receive when you leave your coat in the cloakroom) for that object from the object storage platform which will be saved in the application database. If an application wants to fetch that object, all they would need to do is give the key as part of the GET API and the object would be fetched by the object storage.
Some good examples of object storage APIs are those used by Amazon S3 (the default standard for object storage access), OpenStack Swift, and Azure Blob Service REST API.
Because objects are stored in a flat address space, this makes it easier to locate and retrieve data across regions. This is why object storage has become the preferred solution for data archiving and backup.
Files in a filesystem have a broader set of functions that can be applied to them, including appending data and updating data in place. The programming model is more complex than an object store and is, nowadays at least, almost always accessed programmatically via a “POSIX” style of interface. Generally, the use of CPU and memory is very efficient and there’s a mindset that the filesystem is a private local resource.
Although NFS and SMB do allow for a filesystem to be made available as a multi-tenanted resource, developers usually avoid them because, sometimes, there are subtle differences in how they react compared to “local” filesystems despite their full support for POSIX semantics.
Another big difference between file storage and object storage is that file systems are designed with consistency in mind and are usually accessed over low to moderate latency (50 microseconds – 50 milliseconds) networks. In contrast, object stores are distributed over a shared infrastructure, connected together over low-bandwidth high-latency wide area networks, and their time to the first byte can sometimes be measured in multiples of whole seconds. Performing lots of small (4K – 16K) random reads from an object store is likely to cause frustration and performance problems.
Last but not least, maybe the biggest advantage object storage has is that you can be reasonably sure that anything you put in an object store will remain there until you ask for it again and that it will never run out of space as long as you pay for what you use. These resources generally run at a large scale with built-in replication, version control, automated recovery, etc., and only natural disasters will make the data disappear (but even then, you have easy options to make another copy in another location).
When it comes to filesystems, especially those you’re expecting you or your local team to manage, you can only hope that everything is getting backed up and that it doesn’t fill up accidentally and cause everything to meltdown when you can’t update your data anymore.
Block storage is an alternative to file storage. It takes a file apart into equally-sized data blocks and then stores these blocks as separate pieces of data. Each piece of data has a different address, so they don’t need to be stored in a file structure. To access a file, the operating system uses unique addresses to reassemble it.
Object Storage Benefits
By 2025, IDC estimates thatunstructured data will represent 80% of all data worldwide. Because of this, object storage will become indispensable. But there is more to this new storage architecture than just managing web-generated content.
Infinite Scalability
This is, probably, the most significant advantage of object-based data storage. As we generate more and more data, storage systems need to keep up. But what happens when you try to expand a block-based storage system beyond multiple petabytes? You run into durability issues, hard limitations of your storage infrastructure, or data management issues.
And this is where object storage shines. Because of how objects are stored, whenever you need to, you can simply add more devices/servers in parallel to an object storage cluster for additional processing power and to support higher throughputs.
Reduced Complexity
Because data is stored in a structurally flat data environment, there are fewer chances for performance delay. This improves performance, particularly when managing very large quantities of data.
High Availability
Downtime? What downtime?
Objects remain protected by storing multiple copies of the same data over a distributed system. If a node fails, the data can still be made available; the duplicate can ensure the system continues running with no interruption or performance degradation.
Usually, there are at least three copies of every file stored as a backup which eliminates risk stemming from drive failures, server failures, site failures, and power outages. The unique value for each object is also tied to its content, providing an easy way to check for possible bit-rot by recalculating the value and checking it against the original. Copies can also prevent data corruption.
Metadata Customization
Because objects function as self-contained repositories that include metadata, you can customize the metadata with additional context. This is particularly helpful for extracting business insights or trends, for example.
Affordability
The cost of bulk storage for object store is much less than the block storage for HDFS. Depending on your provider, you can find that object storage costs about 1/3 to 1/5 as much as block storage (keep in mind that HDFS requires block storage). This means that storing the same amount of data in HDFS can be 3 to 5 times more expensive than putting it in object storage.
At the same time, a distributed storage designed for high availability allows less expensive commodity hardware to be used because the data protection is built into the object architecture.
The bottom line is, if you’re working with bulk storage, the majority of your data will be unstructured. Object storage will help you manage your data more efficiently by tracking and indexing files without the need for external software or databases. This will enable you to benefit from new data analytics opportunities.

