
DR in DevOps: How to Guarantee an Effective Disaster Recovery Plan with DevOps
If you’ve followed our blog for a while, you know we often talk about the benefits of DevOps: faster delivery of products and features, more stable environments, improved communication and collaboration, among many others.
Well, actually, a key area where DevOps practices prove most indispensable is Disaster Recovery (DR). Practices such as automation, Continuous Integration (CI), Continuous Delivery (CD), and the use of cloud computing are instrumental in ensuring 100% availability and minimal or no data loss.
In this article, we’ll highlight how following DevOps processes helps you prepare your infrastructure for the worst, along with how Bunnyshell simplifies Disaster Recovery planning.
How to Use DevOps to Make Disaster Recovery Simple and More Effective
We often see one of these 2 scenarios:
- Companies create a Disaster Recovery plan for their application when it’s first put into production, but then neglect to update it as they patch and update the application, which leads to issues during the restoration process. Ongoing DR testing is crucial for ensuring a successful recovery, but it’s often overlooked because it’s time-consuming, expensive, and complex and can disrupt the production environment.
DR testing can impact customers and revenue, which is why some organizations don’t test at all, while others use offsite backups to test. But it’s important to keep in mind that failing to properly test your DR plan can result in extended downtime.
- Alternatively, we also see companies who invest heavily in backup infrastructures that are carbon copies of their production environments and can be used in the event of a service disruption or a disaster. The problem with this strategy is that it’s extremely costly and, with the exception of a few recovery exercises per year, the backup infrastructure stays idle. And one of the core philosophies of DevOps is cost savings.
So here’s how you plan for Disaster Recovery with DevOps:
You take advantage of automation, CI, CD, and CT
Organizations that follow DevOps practices regularly test application changes, so by incorporating DR planning into the DevOps pipeline, you can ensure you manage it along with your application. DevOps enables Continuous Integration (CI) and Continuous Delivery (CD) of product changes and uses automation for deployment and testing. This speeds up application rollouts while minimizing human errors.
By integrating DR planing into your DevOps workflow, you are essentially turning the recovery process into an application deployment process. So when the time comes, your team can use their deployment knowledge and experience and apply it to the recovery process - the automated tools used for moving applications from dev/test into production and vice-versa can be used to failover and recovery, while DR environments that replicate production can be used as DevOps workspaces, instead of letting them stay idle.
This leads us to the next point:
You take advantage of virtualization technologies, storage area networking, and software-defined networking
Hypervisors and virtual machines (VMs) can be scaled up and down in seconds, while software-defined networks can be rerouted and shunted to different connections automatically. Usually, your data is already accessible to the environment, so regular application and operations testing can be done using real data instead of copying it (which is a lengthy process).
In case you need to failover, the monitoring system can change the storage points and shut down the virtual machines. Then, you can manually restore services by reverting all the changes that were made automatically via scripts (Puppet and Chef are most commonly used for this type of orchestration).
The goal is to actually use your “backup” infrastructure instead of letting it sit idle, which is the complete opposite of what DevOps stands for.
You take advantage of object storage
An Overview of Disaster Recovery
Now, we’ve talked quite a bit about how DevOps simplifies DR planning, but what is Disaster Recovery actually? We feel the need to explain this concept more in-depth as we see many organizations mistake it for backup.
Disaster Recovery (DR) is the amount of impact an organization can take during a disaster (disaster = any service-interrupting event, like a power surge, for example). There are 2 key metrics that define the impact: RTO (Recovery Time Objective) and RPO (Recovery Point Objective).
RTO is the maximum amount of time your application can be offline and depends on the SLAs you offer your customers - the promise you make them regarding the availability of your service and the consequences of failing to deliver. RPO is the maximum amount of time during which the data might be lost during an interruption.
Usually, the smaller RTO and RPO values are, the quicker an application will recover from an interruption. Just howquickly entirely depends on the high availability (HA) of the service and DR patterns.
There are 3 DR patterns:
cold DR pattern - the equivalent of having little or no equipment set up for recovery; you’re saving money because you don’t have an idle infrastructure, but it will take you a lot of effort and time to get back running;
warm DR pattern - you have some sort of backup infrastructure, but it’s not the carbon copy of your production environment, so the recovery process is delayed while you retrieve your data;
hot DR pattern - you have a carbon copy of your production environment readily available, including personnel, network systems, power grids, and almost instant backups of your data; you can move from production to backup with 0 downtime, but it will cost you a lot of money (don’t worry, though, as Bunnyshell can help you achieve 0 downtime without huge costs).
Choosing one over the other depends entirely on your organization’s needs.
Disaster Recovery vs. Backups
Although generally, DR and backups have the same goals, they are not the same thing. Backups protect you against host failure or attackers, while having a DR strategy protects you from regional failure like natural disasters.
Here’s a simple explanation of the differences between the two:
Mastering Disaster Recovery with DevOps & Bunnyshell
As part of your Disaster Recovery plan, you can create automatic backups daily for both your application and your database. The retention policy is configurable for periods between 1 week and 1 month - this can be set up from the Virtual Machine ��“OPS” menu > “Backups”. Databases and Applications can have separate backups.
You can opt to use Bunnyshell’s Backup storage (AWS S3), or you can connect your own account (ASW S3, Wasabi, DigitalOcean Spaces, Backblaze B2). The restoration can be performed from the “OPS” main menu, where a listing for all the Virtual Machines that have been ever backed up from that account is present. Note that you can choose and restore individual backups for the Database or Application (files: code base, uploads, etc.).
You can restore the backup in-place (same server, same app), on the same server, but different app, or on a different server altogether, making backups useful in also creating staging environments.
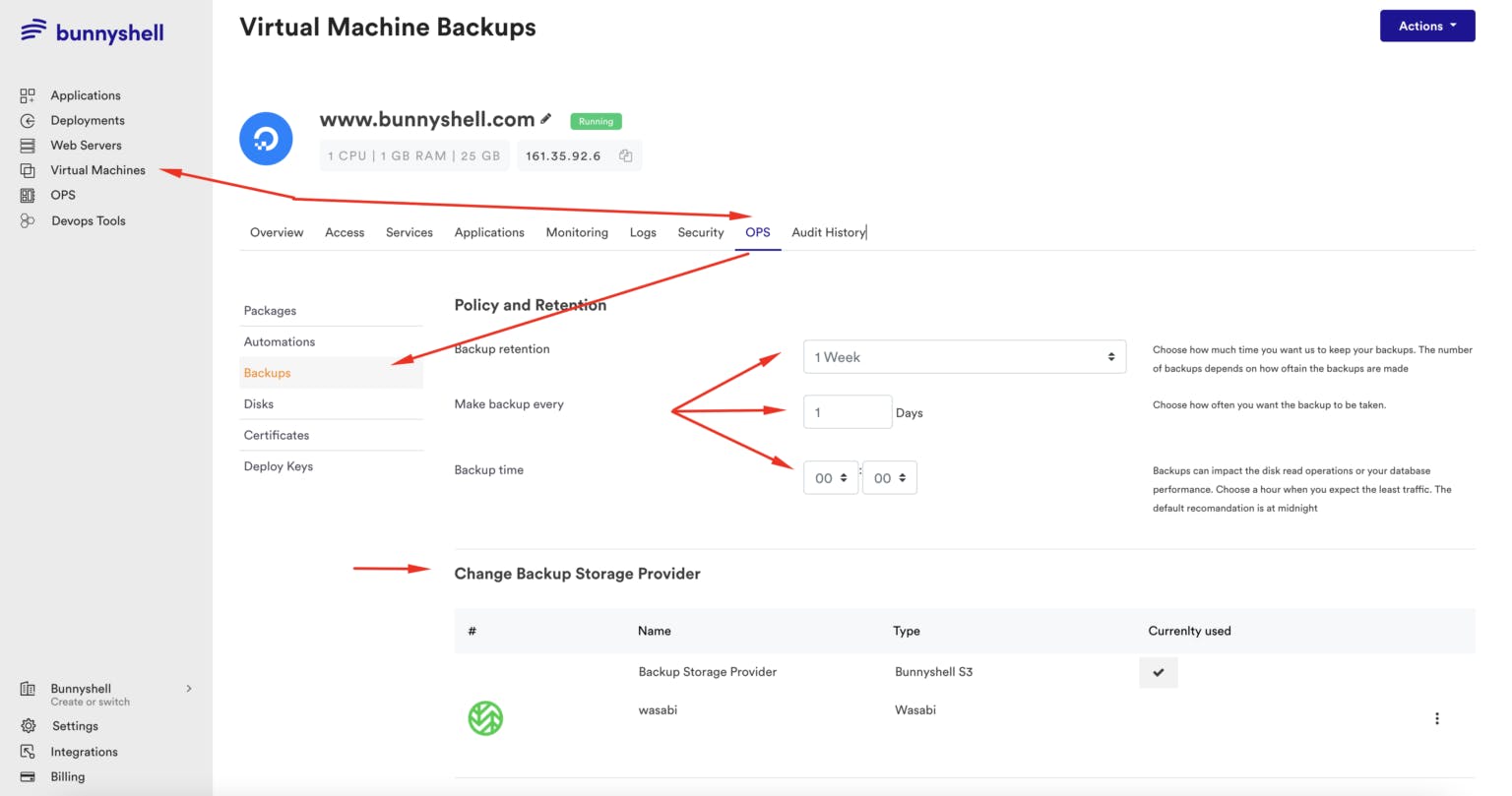
You can also use Snapshots, which creates an image of the entire server instead of only backing up the Database and/or Application files. The snapshot can only be made manually from the same “OPS” menu > “Backups” within a Virtual Machine. Its restoration can also be made from the main “OPS” menu, the “Snapshots” tab.
The snapshot can be restored solely on a new server; no in-place restoration (on the same machine) is available – the image is created to clone a server altogether. Snapshots can be a quick way to recover from a security breach in which you don’t know exactly what has been compromised; just spin up a new server, immediately perform the security updates for the whole stack (OS, packages, application), and change the DNS record to point to the new server. A secondary method of use for snapshots is to create staging/testing environments out of production apps.
So, are you ready to achieve 100% uptime?
